
Figure 1
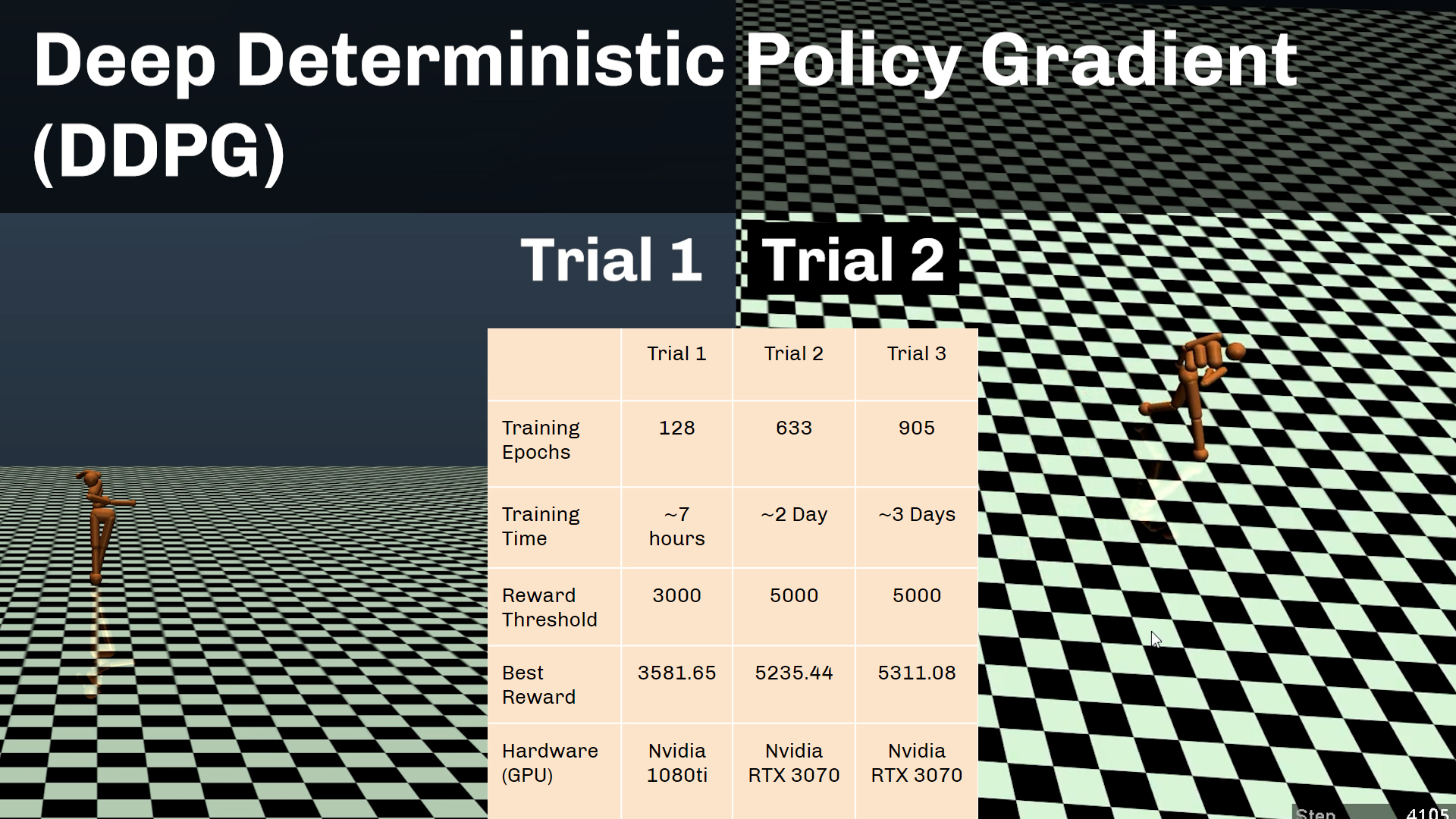
Figure 2
Team 29
Team Members |
Faculty Advisor |
Eric Wang |
Yufeng Wu Sponsor UConn Computer Science & Engineering Department |
sponsored by
Sponsor Image Not Available
“Deep Reinforcement Learning - Humanoid Robot Simulations” is a project that explores the realm of Reinforcement Learning (RL) algorithms and policies for simulating human-like actions. The contributing team utilizes tools including Open AI Gym, Multi-Joint with Contacts (MuJoCo) physics engine, Tianshou RL framework, Tensorflow, Deepmind Control, Pybullet, and Robosumo. Open AI Gym was used as a playground to create environments for XML models designed to perform specific tasks, while serving as the bridge between MuJoCo and Tianshou. The environments define action spaces, steps, rewards used by the agent to control the humanoid model’s movement in an attempt to perform tasks such as standing up or walking. Additionally, custom ant, humanoid, and cheetah based models were developed and trained to understand the capabilities of both MuJoCo and OpenAI Gym. The most successful work was built off of Tianshou, which is a fast-speed modularized framework based on PyTorch, supporting a wide variety of RL policies. The three primary policies used for training with MuJoCo’s “Humanoid-v3” model were Proximal Policy Optimization (PPO), Deep Deterministic Policy Gradient (DDPG), and Twin Layered Deep Deterministic Policy Gradient (TD3). Models trained using PPO were incapable of reaching a high enough reward threshold such that the humanoid could sustain a walking motion, while TD3 produced models that stood stably, but moved minimally. The best results have shown to come from DDPG, where the humanoid was able to find a stable “tip-toeing” position by locking the hips and either extending or locking the arms while in movement. Feel free to send questions to the team! Eric Wang - ericwang@uconn.edu Gurman Singh - gurman.singh@uconn.edu Tianze Ran - tianze.ran@uconn.edu Maggie Cheung - maggie.cheung@uconn.edu Ayman Braik - ayman.braik@uconn.edu
