
Figure 1
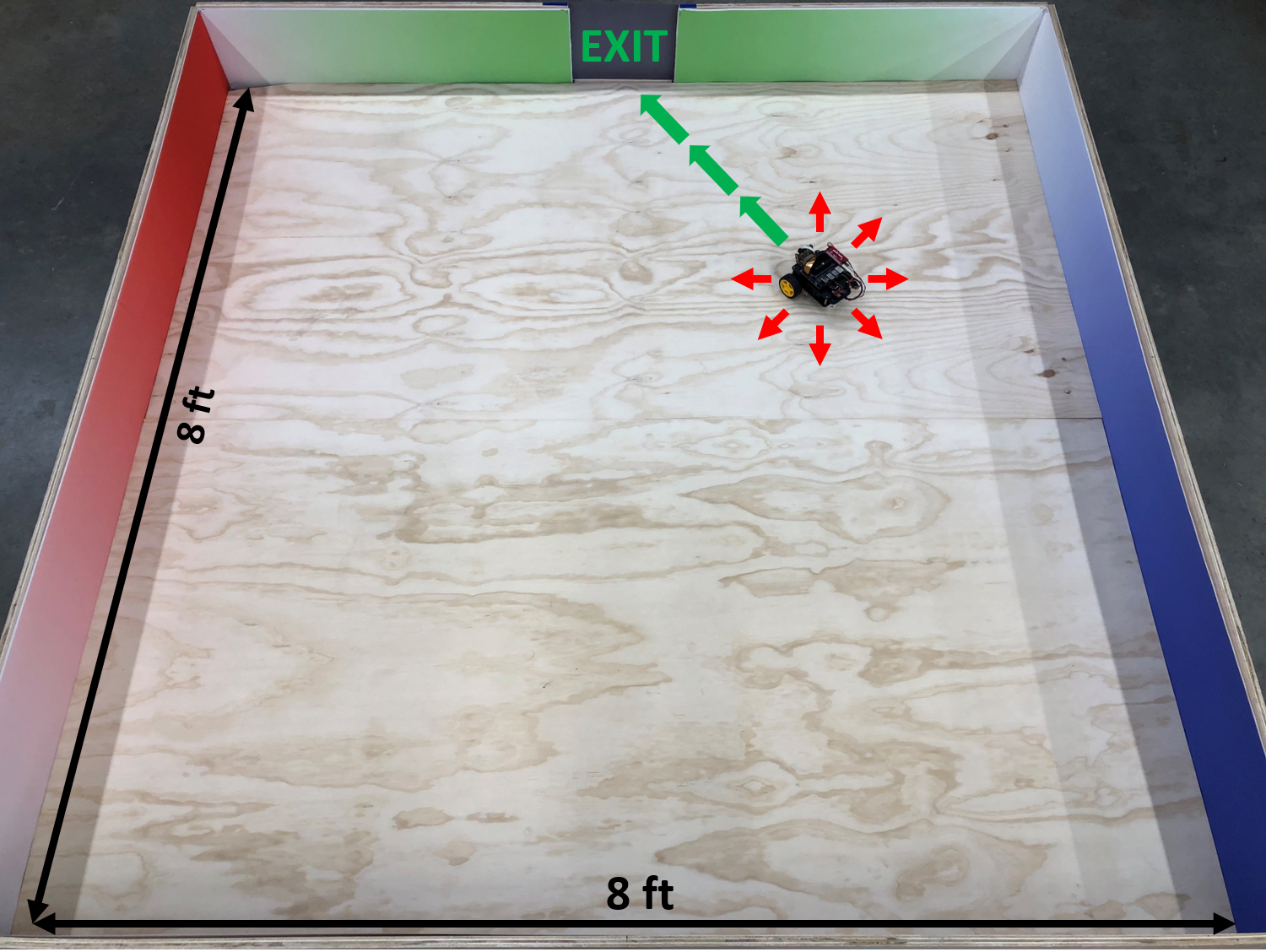
Figure 2
Team 33
Team Members |
Faculty Advisor |
Paul Blum |
Dr. George Lykotrafitis Sponsor UCONN, Dr. Lykotrafitis |
sponsored by
![]()
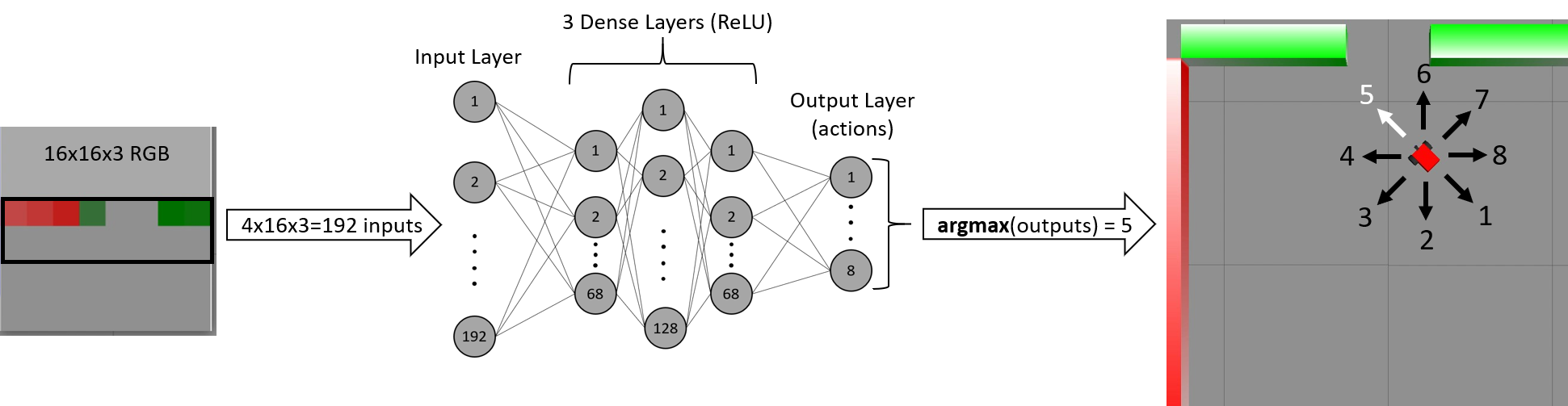
Since 2015, Deep Reinforcement Learning algorithms have had great success in mastering game-theoretic Markov Decision Processes (MDPs), such as Atari games, where an environment can be fully observable to a decision-making agent. Now, researchers are exploring how these algorithms can be used to train robotic agents for partially observable MDPs. In this project, we use Deep Dyna-Q Learning to achieve autonomous robot navigation based on raw image data from an onboard camera. Through interaction with the environment, the robot learns how to evacuate an enclosed space in the shortest possible time. This behavioral policy arises over the course of training in response to the environment’s reward function: a small numerical penalty for each time-step before exiting. A neural network that takes RGB images as inputs is trained, based on the robot’s experiences, to approximate the optimal action-value function. This can be used to achieve time-efficient evacuation by selecting actions with high value from a given state. We built a custom robotics simulation platform using ROS and Gazebo to support virtual training of the robotic agent in an advanced physics simulator with photorealistic graphics capabilities. Our platform is designed for use on a high-performance computing system where training can progress thousands of times faster than possible in real life. We have had great success using the Dyna-Q algorithm with this platform to solve various iterations of the room evacuation problem, including versions with static obstacles and with varying environmental color schemes.
